AI大模型熱算什么「大煉鋼鐵大躍進(jìn)」?

(圖片來源:攝圖網(wǎng))
作者|佘宗明 來源|數(shù)字力場(ID:shuzilichang)
這輪AI大模型熱固然也帶有大干快上的意味,但跟具有特定指向的「大煉鋼鐵」「大躍進(jìn)」無關(guān),畢竟它是市場自發(fā)秩序下的產(chǎn)業(yè)躁動。
01
ChatGPT如此多嬌,引無數(shù)科技企業(yè)競折(對)腰(標(biāo))。
在國內(nèi),首個折腰的是百度。3月16日,文心一言正式發(fā)布。10年在AI上砸了千億的百度,由此拉開了國內(nèi)AI大模型混戰(zhàn)的序幕。
這幾天,AI大模型市場更是燥起來了:
4月9日,基于360GPT大模型開發(fā)的人工智能產(chǎn)品矩陣「360智腦」開放內(nèi)測;
4月10日,「AI四小龍」中的第一股商湯科技發(fā)布「日日新SenseNova」大模型體系;
同日,搜狗創(chuàng)始人王小川正式官宣成立百川智能,表示「爭取年內(nèi)發(fā)布國內(nèi)最好的大模型」,昆侖萬維宣布大模型「天工3.5」4月17日啟動測試……
這其中,最能引爆市場的,要數(shù)全球首個突破10萬億參數(shù)的AI大模型——阿里「通義千問」的面世。
在4月4日用「鳥鳥分鳥」測試了下輿論反應(yīng)、4月7日來了波定向邀測后,4月11日,在2023阿里云峰會現(xiàn)場,阿里正式發(fā)布「通義千問」。
阿里巴巴董事會主席兼CEO、阿里云智能總裁張勇透露,阿里大模型將會「兩條腿走路」:對內(nèi)改造業(yè)務(wù)產(chǎn)品,阿里所有產(chǎn)品都將接入;向外做企業(yè)專屬模型「底座」,可以為每家企業(yè)打造屬于自己的大模型。
短短幾日,國內(nèi)AI大模型賽道鑼鼓喧天、鞭炮齊鳴、紅旗招展、人山人海。
接下來準(zhǔn)備登場的,還有騰訊「混元」、華為「盤古」、京東「言犀」、字節(jié)自研大模型、科大訊飛1+N認(rèn)知智能大模型、浪潮「源1.0」……
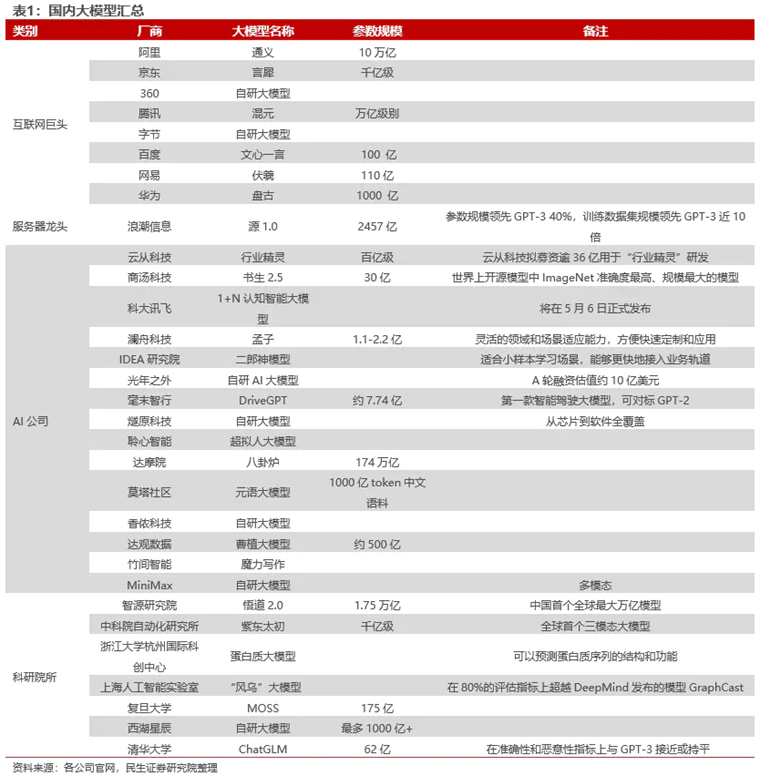
▲國內(nèi)大模型匯總。圖片來源:民生證券研究院。
這跟國外「微軟系」的OpenAI先后推出ChatGPT和GPT-4、谷歌公布LaMDA和PaLM等大模型、Meta發(fā)布開源大模型LLaMA的激烈競爭節(jié)奏遙相呼應(yīng)。
可以這么說:AI大模型熱,熱過東京。
在此情形下,對AI行情過熱的擔(dān)心也隨之出現(xiàn)。
盛產(chǎn)灼見的馮大輝老師就寫了篇《》,感慨「網(wǎng)上涌現(xiàn)出來不少基于ChatGPT的衍生項目,有點像當(dāng)年的小鍋爐土法上馬大煉鋼鐵。推特上現(xiàn)在很熱鬧,更是人均一個GPT小鍋爐。」
他倒沒有抨擊AI大模型熱,只是在對衍生項目「創(chuàng)新的活力在涌動」表示欣賞的同時,對套殼上馬或借機(jī)炒作拉升股價的做法表示了不欣賞。
但在網(wǎng)上,有些人將「大煉鋼鐵」「大躍進(jìn)」的評價,送給了這輪類ChatGPT產(chǎn)品研發(fā)的熱潮。
有人嘲諷,ChatGPT在咱們這離「畝產(chǎn)過萬」不遠(yuǎn)了;也有人調(diào)侃,下個階段該是「全民大模型,ChatGPT進(jìn)萬家」了吧;還有人直言,ChatGPT是懷胎十月的結(jié)果,「湊10對夫妻,想1個月生出小孩」就是胡鬧。
02
在我看來,批評跟風(fēng)追潮無可厚非,但無需將這視作「大煉鋼鐵」「大躍進(jìn)」。
大煉鋼鐵大躍進(jìn),終究是那個特殊年代「計劃」出來的產(chǎn)物。
這輪AI大模型熱固然也帶有大干快上的意味,但與之沒有可比性:它跟具有特定指向的「大煉鋼鐵」「大躍進(jìn)」無關(guān),畢竟它是市場自發(fā)秩序下的產(chǎn)業(yè)躁動。
倒不是說這股熱潮沒有可堪詬病之處,泡沫大、套路多的問題就擺在那。
眼下,就算是很多跟AI八竿子打不著的企業(yè),也在想方設(shè)法往ChatGPT上硬套——就像去年上半年一堆不沾邊的企業(yè)都想往元宇宙上硬蹭那樣。
以至于有人調(diào)侃,干脆弄個ChinaGPT概念股,茅臺、五糧液可以碾壓一大片。
這顯然不太正常。類ChatGPT產(chǎn)品又不是公用WIFI,說蹭就能蹭上。
拿AI大模型研發(fā)來說,阿里云CTO周靖人就表示,動輒超千億參數(shù)的大模型研發(fā),不是單一的算法問題,也不是靠簡單堆積GPU就能實現(xiàn)的,這是囊括了底層算力、網(wǎng)絡(luò)、存儲、大數(shù)據(jù)、AI框架、AI模型等復(fù)雜技術(shù)的系統(tǒng)性工程,需要AI-云計算的全棧技術(shù)能力。
說得通俗些就是:一般玩家沒那個技術(shù)積淀,也沒那個資金規(guī)模。
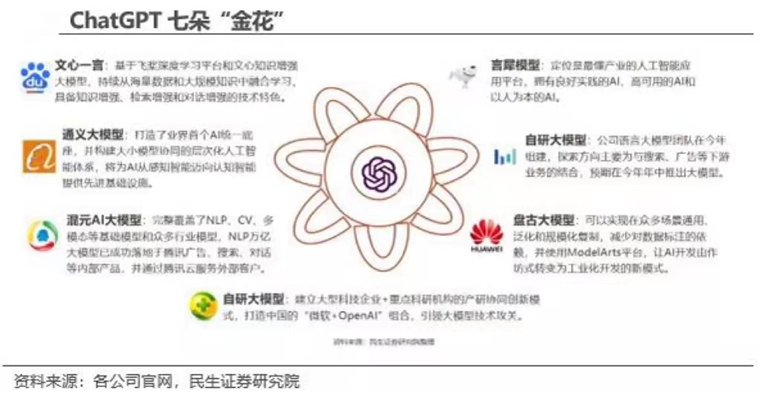
▲國產(chǎn)大模型七朵金花。圖片來源:民生證券研究院。
可眼下AI領(lǐng)域熱火朝天的景象,容易讓人看到國產(chǎn)芯片和操作系統(tǒng)研發(fā)一哄而上、一地雞毛的影子。
很多人擔(dān)心AI大模型熱變成又一個「大煉鋼鐵大躍進(jìn)」,其實是曲線表達(dá)某種顧慮:
這會不會導(dǎo)致產(chǎn)能過剩、資源浪費?
又是否會催生讓股民為泡沫買單的割韭菜游戲?
著眼現(xiàn)實看,兩個問題的答案都是肯定的。
這么多企業(yè)扎堆入場,重復(fù)造輪子的情況在所難免,這勢必會帶來算力浪費。
很多人在談?wù)撍懔r都容易忽略或回避這點:計算會帶來能源消耗和碳排放增量。
2009年谷歌方面曾透露,在谷歌上的每次搜索,會產(chǎn)生0.2克的二氧化碳排放量,哈佛大學(xué)物理學(xué)家阿歷克斯·維茲納爾·格羅斯則稱,每次搜索產(chǎn)生的二氧化碳排放量高達(dá)7克。
隨著技術(shù)進(jìn)步,如今單位算力耗能的確少了,但合起來仍是個天文數(shù)字。在算力已成新生產(chǎn)力的時下,跟計算量指數(shù)級上升伴生的,也是巨大能耗。
第三方分析估計,僅訓(xùn)練GPT-3就消耗了1287兆瓦時,并導(dǎo)致超過550噸二氧化碳當(dāng)量的排放。ChatGPT的參數(shù)更多,碳排放就更大了。
如果說,單車「垃圾圍城」與退押金難題是共享單車平臺將酣戰(zhàn)的負(fù)外部性向社會轉(zhuǎn)嫁,那碳排放就是AI大模型熱的主要負(fù)外部性所在。
至于很多企業(yè)瞄準(zhǔn)股市G點玩對韭當(dāng)割的把戲,只能說是可鄙。
據(jù)說對ChatGPT套皮最多的企業(yè),就來自于咱們這。一堆賣賬號賣課的,已經(jīng)成了第一波靠GPT致富的人了。
調(diào)用ChatGPT大模型沒問題,搞山寨、玩套路,無疑逾越了底線。
對這些問題,該正視就得正視。
03
饒是如此,不能在看到感冒癥狀后,開出的卻是治癌藥。
在輿論場中,主張用「集中力量辦大事」來避免一堆企業(yè)各自「建小高爐大煉鋼鐵」的聲量不小,呼吁有關(guān)部門出來管一管的聲音就更多了。
在有些人看來,「群雄并起」式的無序競爭,必定會帶來AI市場過熱,也帶來重復(fù)性建設(shè)的問題,導(dǎo)致本該用來攻堅的大量資金彈藥被浪費。
他們認(rèn)為,該將所有科技企業(yè)的AI技術(shù)研發(fā)「擰成一股繩」、組成「抗OpenAI聯(lián)盟」,或是該由AI「國家隊」來主攻,科技企業(yè)打配合。
一邊將AI大模型熱說成裹著計劃底色的「大煉鋼鐵大躍進(jìn)」,一方面開出帶有計劃烙印的藥方,這著實有些分裂。
事實上,擔(dān)心當(dāng)前局面下的AI大模型熱變成翻版「大煉鋼鐵大躍進(jìn)」,或許是杞人之憂。
即便是「非理性繁榮」,AI領(lǐng)域的市場競爭白熱化,對中國AI產(chǎn)業(yè)的整體發(fā)展也是好事。

▲圍繞AI大模型,國內(nèi)外科技龍頭正展開激烈競爭。圖片來源:德邦研究所。
管理學(xué)者迪伊·沃德·霍克說:「我們正好處在一個歷時400年的時代即將結(jié)束、另一個時代正沖破阻力而來這樣一個時刻。」
而通用AI將成為提升21世紀(jì)整體社會生產(chǎn)力最為重要的賦能技術(shù),AI的iPhone時刻已到……諸如此類的敘事,就與之扣合。
這時候,科技企業(yè)想搶灘布局未來,再正常不過。雖說AI大模型很燒錢,可場景化應(yīng)用有錢景。百度阿里的「模型+工具平臺+生態(tài)」三層共建模式,就連著廣闊的前景。
可在很多人看來,AI研發(fā)就該十指成拳,而非各自為戰(zhàn),不然沒法呈現(xiàn)出「中國AI軍團(tuán)」的合力。
問題來了:國內(nèi)頭部科技企業(yè)都在摩拳擦掌,你讓誰上場,讓誰退出?是抽簽決定,還是競標(biāo)篩選?
但這么一哄而上,不會造成資源浪費嗎?有些人興許會這樣反駁。
就這么說吧:要看到充分市場競爭下的資源浪費,更要看到缺乏足夠競爭下的資源浪費,后者通常比前者更嚴(yán)重。
換句話說:競爭必然帶來浪費,但不競爭經(jīng)常帶來更大的浪費。
應(yīng)看到,這些年來,中國市場的強(qiáng)敏捷性,讓它對每個風(fēng)口的反應(yīng)能力都極快,得益于數(shù)字基建與制造能力上的積淀,國內(nèi)許多企業(yè)抓住了新興制造領(lǐng)域以往很難抓住的機(jī)遇。
比如,智能手機(jī)。
iPhone出來后,華為、小米、oppo、vivo都跟上了,360、聯(lián)想、樂視、魅族、錘子也接連登場,華強(qiáng)北也跟著躁動不安,將國內(nèi)外手機(jī)市場卷成了紅海。
浪費嗎?當(dāng)然會有產(chǎn)能浪費。但正是憑著激烈競爭,在功能機(jī)時代沒有姓名的中國手機(jī)制造業(yè),在移動互聯(lián)網(wǎng)時代躋身世界前列。
再如,新能源汽車。
特斯拉出來后,比亞迪和蔚小理都跟上了,哪吒問界極氪零跑等也緊隨其后,去年10月,里斯戰(zhàn)略定位咨詢在《全球新能源汽車品類趨勢研究報告》中指出,中國新能源汽車品牌的數(shù)量高達(dá)150多個,整車制造企業(yè)數(shù)量有 198 家,系全球最多。數(shù)據(jù)顯示,我國現(xiàn)存新能源汽車相關(guān)企業(yè)60.58萬家。
浪費嗎?同樣會有各種資源浪費。但也是憑著激烈競爭,在燃油車時代身處德系日系巨頭夾縫的中國汽車制造業(yè),在新能源汽車時代做大做強(qiáng)。
依照部分人的邏輯,之前一堆企業(yè)下場造手機(jī)造車,何嘗不是大煉鋼鐵大躍進(jìn)?
這里面,圈地套補(bǔ)之類的亂象確實該治理。但就所謂的產(chǎn)能浪費而言,它本質(zhì)上也是由此鍛造出來的強(qiáng)大產(chǎn)業(yè)鏈供應(yīng)鏈能力的成本。
沒有此前的白熱化競爭及伴生成本,中國制造整體實力何以做強(qiáng)?
04
說起來,資源浪費是很多人反對充分化市場競爭的關(guān)鍵依據(jù)——雖說他們會說自己反對的不是競爭,而是「無序競爭」。
之前互聯(lián)網(wǎng)企業(yè)扎堆「造車」時,不少人就認(rèn)為,這會帶來過度建設(shè)。
經(jīng)濟(jì)學(xué)家曹遠(yuǎn)征就說得挺好:市場過程中有失靈,有弊端,但是你要理解,它的本質(zhì)是,只要市場競爭,就一定會有過剩,然后靠競爭優(yōu)勝劣汰出來,這是它規(guī)律性的表現(xiàn)。
他對「先過剩供給再優(yōu)勝劣汰,付出的代價太高」的說法駁斥道:
這個想法是錯誤的。計劃經(jīng)濟(jì)就是這個想法,叫人為配置資源。但最后我們發(fā)現(xiàn),所有事都是事后知道的。你說當(dāng)年我要這樣就好了,但是你在當(dāng)年是不知道這些情況的。你只有選擇了多樣性,然后才會優(yōu)勝劣汰出最終的選擇。
看不見的手就是看不見的,你想努力把它看見,但最后發(fā)現(xiàn)你還是看不見。
模擬市場是模擬不出來的,這就是市場的魅力。回頭看時,市場經(jīng)濟(jì)發(fā)展中,好像是會出現(xiàn)重復(fù)建設(shè),過剩浪費,但它是有效的。計劃經(jīng)濟(jì)看起來也產(chǎn)生了很多東西,但計劃經(jīng)濟(jì)造成的浪費,是永久性的。
在他看來,肯為創(chuàng)新承擔(dān)風(fēng)險的企業(yè)家有著天然的敏感性,他們會發(fā)現(xiàn)市場的訴求,打通市場的堵點。
這跟哈耶克說的有相通之處:社會的發(fā)展就是要增加機(jī)遇,促使個人在天賦和環(huán)境間形成某種特別的組合。
那有沒有辦法去減少激烈競爭下的「非必要浪費」?
有些學(xué)界業(yè)界人士將目光看向了包括超算算力底座在內(nèi)的國家級數(shù)字化基建。
如平安首席科學(xué)家肖京就認(rèn)為,在未來人工智能的大模型浪潮中,我國更應(yīng)該利用集中優(yōu)勢力量的體制優(yōu)勢,避免各家分別「建小高爐大煉鋼鐵」,而是整體統(tǒng)籌,加快打造國家級數(shù)字化底座建設(shè)。
他主張,通過協(xié)調(diào)各方資源,引導(dǎo)重大科技基礎(chǔ)設(shè)施、高校及科研院所、頭部企業(yè)共同參與,集中貢獻(xiàn)算力、數(shù)據(jù)、資金、人才及場景等各方資源,建立共享、共建、共用、共創(chuàng)機(jī)制和數(shù)字化底座的市場化運營機(jī)制,強(qiáng)化通用數(shù)字化建設(shè)底座的打造。
周鴻祎也提出將政、產(chǎn)、學(xué)、研、用打通,打造「理想主義+實用主義」的科研生態(tài)的設(shè)想。
他提出,應(yīng)該發(fā)揮新型舉國體制,把知名大學(xué)、國家實驗室、科研機(jī)構(gòu)、科研體系和已在大模型自然語言處理有跟蹤和研究的科技公司結(jié)合起來,通過合作方式推進(jìn)。既然技術(shù)上別人已經(jīng)領(lǐng)先了,不要再去重新「大煉鋼鐵」,重復(fù)發(fā)明輪子。
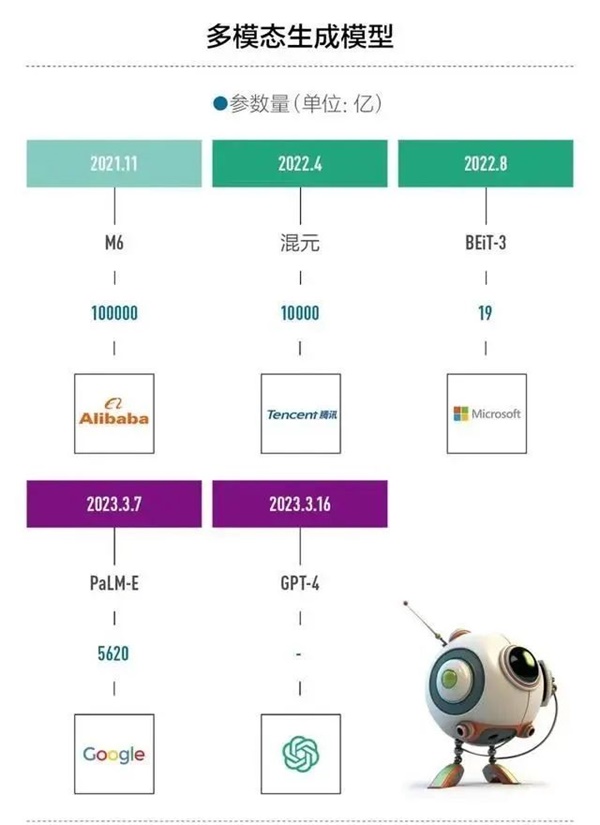
▲幾大頭部AI大模型的參數(shù)量。圖片來源:第一財經(jīng)。
這類想法,似乎契合經(jīng)濟(jì)學(xué)家常修澤描述的情形:非市場化的「社會巨型科層」與新古典的「純粹市場體系」從組織資源配置的「兩極」向「中間地帶」靠攏,以尋求現(xiàn)代市場與科層結(jié)構(gòu)的新組合。它是否可取可行,仍待討論。
可以肯定的是,ChatGPT是市場創(chuàng)新生態(tài)體系上結(jié)出的果子,打造AI大模型也需要篤定市場導(dǎo)向。這并非要拒斥算力基礎(chǔ)設(shè)施的供給,只是說要讓有形的手止于該止的地方,其他的交給無形的手來。
在激烈的市場競爭下,有的企業(yè)也會以開放為手段提升自身競爭力。阿里云表示要為企業(yè)級市場提供普惠AI基礎(chǔ)設(shè)施,幫企業(yè)搭建專屬模型,就是提升自身競爭力的方式。
事實證明,大浪淘沙,最終會淘出最具競爭力的「碩果」來。
05
說到底,沒必要將AI大模型熱視作「大煉鋼鐵大躍進(jìn)」。即便存在所謂的「過度競爭」,那也是生成式AI發(fā)展到Gartner第二階段「期望膨脹期」的表現(xiàn)。
吐槽泡沫沒問題,但不能對中國版ChatGPT持有雙標(biāo)式矛盾心態(tài):AI大模型出來前,批中國科技企業(yè)沒有硬科技實力;多個AI大模型出來后,又批市場過熱。
認(rèn)為AI大模型要「不多不少」才好,未嘗不是「計劃思維」在作祟。
只要遵循市場規(guī)律,不隨意拉踩也不揠苗助長,在當(dāng)前的數(shù)字基建支撐下,國內(nèi)科技企業(yè)們自然會有足夠動力,去用AI技術(shù)突破獲得市場地位。
不要只認(rèn)為AI技術(shù)攻堅攸關(guān)國家數(shù)字主權(quán),這類前沿技術(shù)也關(guān)乎企業(yè)未來競爭力。誰又不想抓住未來的Window、iOS、Android呢?
當(dāng)此之時,社會該做的,也許就是厚植創(chuàng)新沃土,為創(chuàng)新激勵型環(huán)境營造做加法。
厄休拉·M ·富蘭克林在《技術(shù)的真相》中說:
(技術(shù))尺寸是生長的自然結(jié)果,但生長本身是不能被強(qiáng)取的,它只能通過提供一種適宜的環(huán)境而得到培育和鼓勵。
生長是發(fā)生性的,不是制造出來的。在一個生長模式之內(nèi),人類所能做的就是發(fā)現(xiàn)對生長而言最適宜的條件,并努力滿足這些條件。在目前每一種環(huán)境中,生長有機(jī)體都是按自身的比率發(fā)展的。
要想讓中國版ChatGPT加速成長,就該給自發(fā)性市場競爭以包容空間,而非輕易將白熱化競爭斥為「大煉鋼鐵」「大躍進(jìn)」。
編者按:本文轉(zhuǎn)載自微信公眾號:數(shù)字力場(ID:shuzilichang),作者:佘宗明


前瞻經(jīng)濟(jì)學(xué)人
專注于中國各行業(yè)市場分析、未來發(fā)展趨勢等。掃一掃立即關(guān)注。
前瞻產(chǎn)業(yè)研究院
中國產(chǎn)業(yè)咨詢領(lǐng)導(dǎo)者,專業(yè)提供產(chǎn)業(yè)規(guī)劃、產(chǎn)業(yè)申報、產(chǎn)業(yè)升級轉(zhuǎn)型、產(chǎn)業(yè)園區(qū)規(guī)劃、可行性報告等領(lǐng)域解決方案,掃一掃關(guān)注。相關(guān)閱讀RELEVANT



























